

-


编程语言
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 Vivian
2018-07-03
来源 :
阅读 933
评论 0
Vivian
2018-07-03
来源 :
阅读 933
评论 0
摘要:本文主要向大家介绍了【JAVA语言并发编程】之十九:并发新特性—Executor框架与线程池(含代码),通过具体的内容向大家展示,希望对大家学习JAVA语言有所帮助。
本文主要向大家介绍了【JAVA语言并发编程】之十九:并发新特性—Executor框架与线程池(含代码),通过具体的内容向大家展示,希望对大家学习JAVA语言有所帮助。
Executor框架简介
在Java 5之后,并发编程引入了一堆新的启动、调度和管理线程的API。Executor框架便是Java 5中引入的,其内部使用了线程池机制,它在java.util.cocurrent 包下,通过该框架来控制线程的启动、执行和关闭,可以简化并发编程的操作。因此,在Java 5之后,通过Executor来启动线程比使用Thread的start方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免this逃逸问题——如果我们在构造器中启动一个线程,因为另一个任务可能会在构造器结束之前开始执行,此时可能会访问到初始化了一半的对象用Executor在构造器中。
Executor框架包括:线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable等。
Executor接口中之定义了一个方法execute(Runnable command),该方法接收一个Runable实例,它用来执行一个任务,任务即一个实现了Runnable接口的类。ExecutorService接口继承自Executor接口,它提供了更丰富的实现多线程的方法,比如,ExecutorService提供了关闭自己的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以调用ExecutorService的shutdown()方法来平滑地关闭 ExecutorService,调用该方法后,将导致ExecutorService停止接受任何新的任务且等待已经提交的任务执行完成(已经提交的任务会分两类:一类是已经在执行的,另一类是还没有开始执行的),当所有已经提交的任务执行完毕后将会关闭ExecutorService。因此我们一般用该接口来实现和管理多线程。
ExecutorService的生命周期包括三种状态:运行、关闭、终止。创建后便进入运行状态,当调用了shutdown()方法时,便进入关闭状态,此时意味着ExecutorService不再接受新的任务,但它还在执行已经提交了的任务,当素有已经提交了的任务执行完后,便到达终止状态。如果不调用shutdown()方法,ExecutorService会一直处在运行状态,不断接收新的任务,执行新的任务,服务器端一般不需要关闭它,保持一直运行即可。
Executors提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线 程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
这四种方法都是用的Executors中的ThreadFactory建立的线程,下面就以上四个方法做个比较
一般来说,CachedTheadPool在程序执行过程中通常会创建与所需数量相同的线程,然后在它回收旧线程时停止创建新线程,因此它是合理的Executor的首选,只有当这种方式会引发问题时(比如需要大量长时间面向连接的线程时),才需要考虑用FixedThreadPool。(该段话摘自《Thinking in Java》第四版)
Executor执行Runnable任务
通过Executors的以上四个静态工厂方法获得 ExecutorService实例,而后调用该实例的execute(Runnable command)方法即可。一旦Runnable任务传递到execute()方法,该方法便会自动在一个线程上执行。下面是是Executor执行Runnable任务的示例代码:
[java] view plain copy
1. import java.util.concurrent.ExecutorService;
2. import java.util.concurrent.Executors;
3.
4. public class TestCachedThreadPool{
5. public static void main(String[] args){
6. ExecutorService executorService = Executors.newCachedThreadPool();
7. // ExecutorService executorService = Executors.newFixedThreadPool(5);
8. // ExecutorService executorService = Executors.newSingleThreadExecutor();
9. for (int i = 0; i < 5; i++){
10. executorService.execute(new TestRunnable());
11. System.out.println("************* a" + i + " *************");
12. }
13. executorService.shutdown();
14. }
15. }
16.
17. class TestRunnable implements Runnable{
18. public void run(){
19. System.out.println(Thread.currentThread().getName() + "线程被调用了。");
20. }
21. }
某次执行后的结果如下:
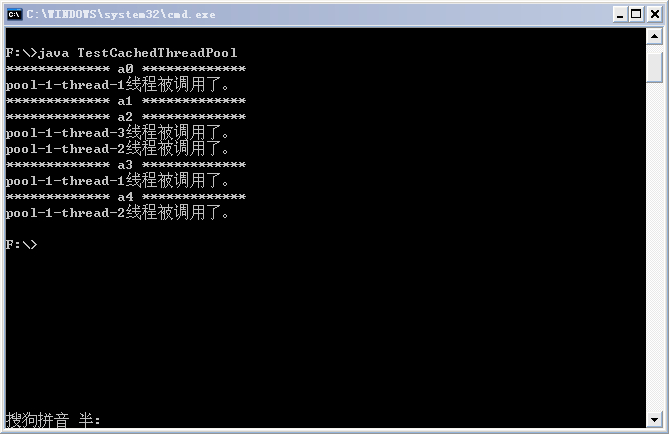
从结果中可以看出,pool-1-thread-1和pool-1-thread-2均被调用了两次,这是随机的,execute会首先在线程池中选择一个已有空闲线程来执行任务,如果线程池中没有空闲线程,它便会创建一个新的线程来执行任务。
Executor执行Callable任务
在Java 5之后,任务分两类:一类是实现了Runnable接口的类,一类是实现了Callable接口的类。两者都可以被ExecutorService执行,但是Runnable任务没有返回值,而Callable任务有返回值。并且Callable的call()方法只能通过ExecutorService的submit(Callable<T> task) 方法来执行,并且返回一个 <T>Future<T>,是表示任务等待完成的 Future。
Callable接口类似于Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常而Callable又返回结果,而且当获取返回结果时可能会抛出异常。Callable中的call()方法类似Runnable的run()方法,区别同样是有返回值,后者没有。
当将一个Callable的对象传递给ExecutorService的submit方法,则该call方法自动在一个线程上执行,并且会返回执行结果Future对象。同样,将Runnable的对象传递给ExecutorService的submit方法,则该run方法自动在一个线程上执行,并且会返回执行结果Future对象,但是在该Future对象上调用get方法,将返回null。
下面给出一个Executor执行Callable任务的示例代码:
[java] view plain copy
1. import java.util.ArrayList;
2. import java.util.List;
3. import java.util.concurrent.*;
4.
5. public class CallableDemo{
6. public static void main(String[] args){
7. ExecutorService executorService = Executors.newCachedThreadPool();
8. List<Future<String>> resultList = new ArrayList<Future<String>>();
9.
10. //创建10个任务并执行
11. for (int i = 0; i < 10; i++){
12. //使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中
13. Future<String> future = executorService.submit(new TaskWithResult(i));
14. //将任务执行结果存储到List中
15. resultList.add(future);
16. }
17.
18. //遍历任务的结果
19. for (Future<String> fs : resultList){
20. try{
21. while(!fs.isDone);//Future返回如果没有完成,则一直循环等待,直到Future返回完成
22. System.out.println(fs.get()); //打印各个线程(任务)执行的结果
23. }catch(InterruptedException e){
24. e.printStackTrace();
25. }catch(ExecutionException e){
26. e.printStackTrace();
27. }finally{
28. //启动一次顺序关闭,执行以前提交的任务,但不接受新任务
29. executorService.shutdown();
30. }
31. }
32. }
33. }
34.
35.
36. class TaskWithResult implements Callable<String>{
37. private int id;
38.
39. public TaskWithResult(int id){
40. this.id = id;
41. }
42.
43. /**
44. * 任务的具体过程,一旦任务传给ExecutorService的submit方法,
45. * 则该方法自动在一个线程上执行
46. */
47. public String call() throws Exception {
48. System.out.println("call()方法被自动调用!!! " + Thread.currentThread().getName());
49. //该返回结果将被Future的get方法得到
50. return "call()方法被自动调用,任务返回的结果是:" + id + " " + Thread.currentThread().getName();
51. }
52. }
某次执行结果如下:
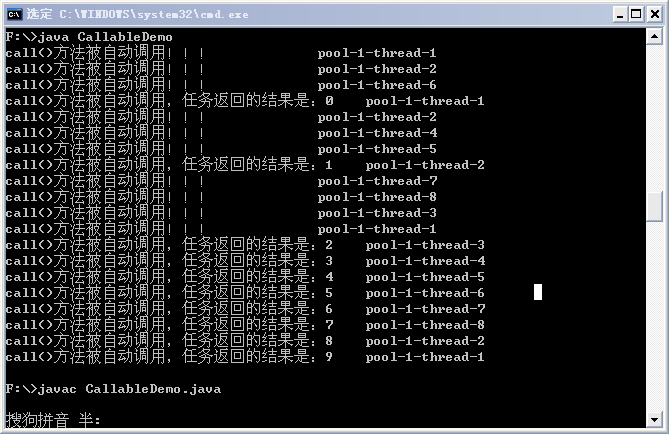
从结果中可以同样可以看出,submit也是首先选择空闲线程来执行任务,如果没有,才会创建新的线程来执行任务。另外,需要注意:如果Future的返回尚未完成,则get()方法会阻塞等待,直到Future完成返回,可以通过调用isDone()方法判断Future是否完成了返回。
自定义线程池
自定义线程池,可以用ThreadPoolExecutor类创建,它有多个构造方法来创建线程池,用该类很容易实现自定义的线程池,这里先贴上示例程序:
[java] view plain copy
1. import java.util.concurrent.ArrayBlockingQueue;
2. import java.util.concurrent.BlockingQueue;
3. import java.util.concurrent.ThreadPoolExecutor;
4. import java.util.concurrent.TimeUnit;
5.
6. public class ThreadPoolTest{
7. public static void main(String[] args){
8. //创建等待队列
9. BlockingQueue<Runnable> bqueue = new ArrayBlockingQueue<Runnable>(20);
10. //创建线程池,池中保存的线程数为3,允许的最大线程数为5
11. ThreadPoolExecutor pool = new ThreadPoolExecutor(3,5,50,TimeUnit.MILLISECONDS,bqueue);
12. //创建七个任务
13. Runnable t1 = new MyThread();
14. Runnable t2 = new MyThread();
15. Runnable t3 = new MyThread();
16. Runnable t4 = new MyThread();
17. Runnable t5 = new MyThread();
18. Runnable t6 = new MyThread();
19. Runnable t7 = new MyThread();
20. //每个任务会在一个线程上执行
21. pool.execute(t1);
22. pool.execute(t2);
23. pool.execute(t3);
24. pool.execute(t4);
25. pool.execute(t5);
26. pool.execute(t6);
27. pool.execute(t7);
28. //关闭线程池
29. pool.shutdown();
30. }
31. }
32.
33. class MyThread implements Runnable{
34. @Override
35. public void run(){
36. System.out.println(Thread.currentThread().getName() + "正在执行。。。");
37. try{
38. Thread.sleep(100);
39. }catch(InterruptedException e){
40. e.printStackTrace();
41. }
42. }
43. }
运行结果如下:
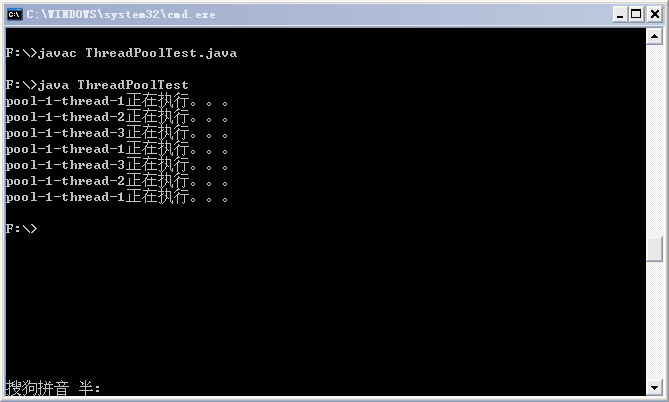
从结果中可以看出,七个任务是在线程池的三个线程上执行的。这里简要说明下用到的ThreadPoolExecuror类的构造方法中各个参数的含义。
public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue)
corePoolSize:线程池中所保存的核心线程数,包括空闲线程。
maximumPoolSize:池中允许的最大线程数。
keepAliveTime:线程池中的空闲线程所能持续的最长时间。
unit:持续时间的单位。
workQueue:任务执行前保存任务的队列,仅保存由execute方法提交的Runnable任务。
根据ThreadPoolExecutor源码前面大段的注释,我们可以看出,当试图通过excute方法讲一个Runnable任务添加到线程池中时,按照如下顺序来处理:
1、如果线程池中的线程数量少于corePoolSize,即使线程池中有空闲线程,也会创建一个新的线程来执行新添加的任务;
2、如果线程池中的线程数量大于等于corePoolSize,但缓冲队列workQueue未满,则将新添加的任务放到workQueue中,按照FIFO的原则依次等待执行(线程池中有线程空闲出来后依次将缓冲队列中的任务交付给空闲的线程执行);
3、如果线程池中的线程数量大于等于corePoolSize,且缓冲队列workQueue已满,但线程池中的线程数量小于maximumPoolSize,则会创建新的线程来处理被添加的任务;
4、如果线程池中的线程数量等于了maximumPoolSize,有4种才处理方式(该构造方法调用了含有5个参数的构造方法,并将最后一个构造方法为RejectedExecutionHandler类型,它在处理线程溢出时有4种方式,这里不再细说,要了解的,自己可以阅读下源码)。
总结起来,也即是说,当有新的任务要处理时,先看线程池中的线程数量是否大于corePoolSize,再看缓冲队列workQueue是否满,最后看线程池中的线程数量是否大于maximumPoolSize。
另外,当线程池中的线程数量大于corePoolSize时,如果里面有线程的空闲时间超过了keepAliveTime,就将其移除线程池,这样,可以动态地调整线程池中线程的数量。
我们大致来看下Executors的源码,newCachedThreadPool的不带RejectedExecutionHandler参数(即第五个参数,线程数量超过maximumPoolSize时,指定处理方式)的构造方法如下:
[java] view plain copy
1. public static ExecutorService newCachedThreadPool() {
2. return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
3. 60L, TimeUnit.SECONDS,
4. new SynchronousQueue<Runnable>());
5. }
它将corePoolSize设定为0,而将maximumPoolSize设定为了Integer的最大值,线程空闲超过60秒,将会从线程池中移除。由于核心线程数为0,因此每次添加任务,都会先从线程池中找空闲线程,如果没有就会创建一个线程(SynchronousQueue<Runnalbe>决定的,后面会说)来执行新的任务,并将该线程加入到线程池中,而最大允许的线程数为Integer的最大值,因此这个线程池理论上可以不断扩大。
再来看newFixedThreadPool的不带RejectedExecutionHandler参数的构造方法,如下:
[java] view plain copy
1. public static ExecutorService newFixedThreadPool(int nThreads) {
2. return new ThreadPoolExecutor(nThreads, nThreads,
3. 0L, TimeUnit.MILLISECONDS,
4. new LinkedBlockingQueue<Runnable>());
5. }
它将corePoolSize和maximumPoolSize都设定为了nThreads,这样便实现了线程池的大小的固定,不会动态地扩大,另外,keepAliveTime设定为了0,也就是说线程只要空闲下来,就会被移除线程池,敢于LinkedBlockingQueue下面会说。
下面说说几种排队的策略:
1、直接提交。缓冲队列采用 SynchronousQueue,它将任务直接交给线程处理而不保持它们。如果不存在可用于立即运行任务的线程(即线程池中的线程都在工作),则试图把任务加入缓冲队列将会失败,因此会构造一个新的线程来处理新添加的任务,并将其加入到线程池中。直接提交通常要求无界 maximumPoolSizes(Integer.MAX_VALUE) 以避免拒绝新提交的任务。newCachedThreadPool采用的便是这种策略。
2、无界队列。使用无界队列(典型的便是采用预定义容量的 LinkedBlockingQueue,理论上是该缓冲队列可以对无限多的任务排队)将导致在所有 corePoolSize 线程都工作的情况下将新任务加入到缓冲队列中。这样,创建的线程就不会超过 corePoolSize,也因此,maximumPoolSize 的值也就无效了。当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列。newFixedThreadPool采用的便是这种策略。
3、有界队列。当使用有限的 maximumPoolSizes 时,有界队列(一般缓冲队列使用ArrayBlockingQueue,并制定队列的最大长度)有助于防止资源耗尽,但是可能较难调整和控制,队列大小和最大池大小需要相互折衷,需要设定合理的参数。
本文由职坐标整理并发布,希望对同学们有所帮助。了解更多详情请关注编程语言JAVA频道!
 喜欢 | 2
喜欢 | 2
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




